网络爬虫是一种技术,指的是访问页面和发现网站上的url。当在Python网页抓取应用中使用时,它可以从许多页面收集大量数据。在本教程中,您将通过逐步示例学习如何构建Python网络爬虫。
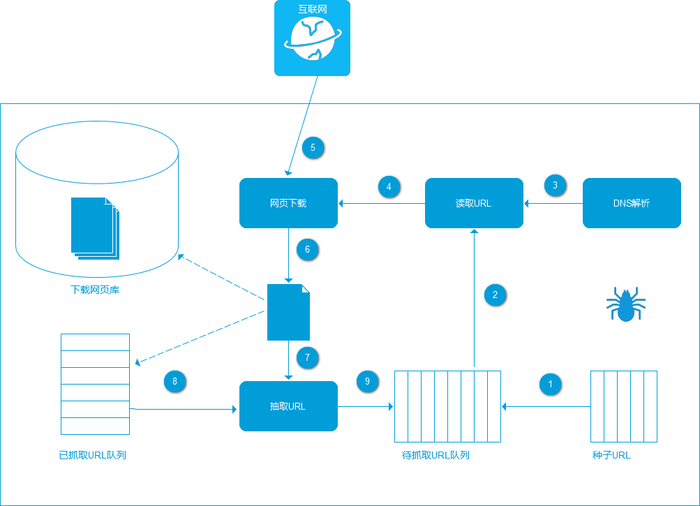
爬虫的逻辑
- 访问:通过指定的url读取到html页面
- 下载:将html源码下载爬虫程序所在机器上
- 分析:分析html结构获取指定标签内的信息
- 保存:保存获取到的目标信息
爬虫的应用
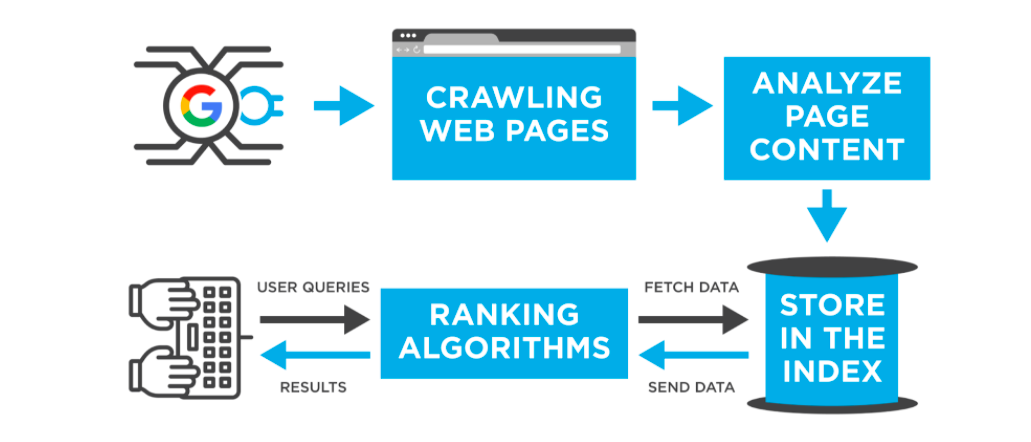
搜索引擎
顺便提一句,其实像百度,Bing,谷歌等用于搜索互联网知识的工具(一般大家称为搜索引擎)也是一种爬虫。
谷歌在早期就开发了强大的网页爬取技术,能快速抓取和索引海量的网页数据。这为构建全面的搜索引擎打下了基础。
谷歌的创始人巧妙利用网页之间的链接关系,开发出PageRank算法,能准确评估网页的重要性和排名。这种基于网页质量的排序方式大大提升了搜索结果的相关性。
其他应用
- 内容采集
通过爬虫可以从网页、社交媒体、视频网站等渠道采集各种类型的信息,如新闻、产品信息、用户评论等。这些数据可用于分析、决策支持等。
- 监控和预警
爬虫可用于持续监控网站、交易平台等,发现异常情况并触发预警。如监控商品价格变动、检测违法信息等。
- 搜索引擎
搜索引擎的核心就是通过爬虫不断发现、抓取和整理网络上的信息,构建搜索索引,为用户提供更好的搜索服务。
- 舆情分析
爬虫可帮助收集来自社交媒体、论坛等的口碑信息、评论等,用于分析舆论走向,支持企业做出更好的决策。
- 数据挖掘
从网页中提取结构化数据,进行数据分析和建模,可发现隐藏的价值信息,支持商业决策。
- 竞争分析
通过爬取竞争对手的网页信息,如产品信息、价格、促销活动等,了解行业动态,制定更有针对性的竞争策略。
- 自动化测试
在软件测试中,爬虫可用于自动化地测试网站或应用的功能和性能。

